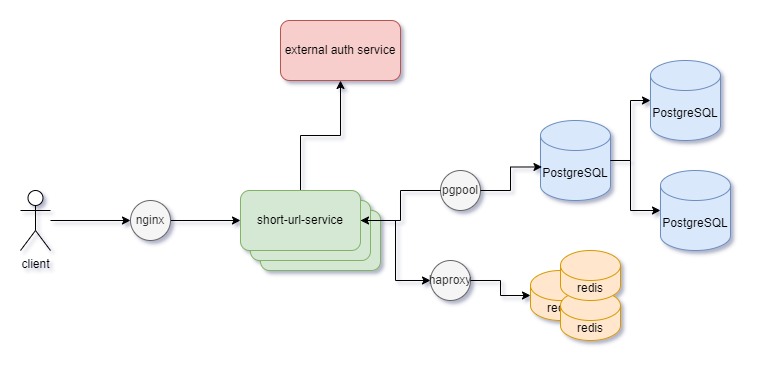
Design of the Short-URL-Service
Functional requirements
- сокращать URL’ы
- URL’ы должны быть как можно короче
- клик по сокращенному URL’у должен перенаправлять на длинный URL
- URL’ы должны храниться в системе 100 лет
Non-functional requirements
- без падений, постоянная работа
- перенаправление URL должно быть быстрым
- сервис будет частью системы, в которой уже есть авторизация, где каждый запрос обогащен информацией о пользователе
Database scheme
Что необходимо хранить:
- сокращенный URL
- оригинальный URL
- время создания
- идентификатор пользователя

Сколько будет занимать одна запись?
- short_url
- достаточно хранить один хеш без, который, как выяснили выше составляет 5 символов
- 5 символов в utf-8 кодировке будут занимать 5 байт
- original_url
- может быть каким угодно, но браузерный лимит составляет 2048 символов
- 2048 символов в utf-8 кодировке будут занимать 2048 байт
- created_at
- timestamp в postgres занимает 8 байт
- user_id
- тип данных uuid в postgres занимает 16 байт
В сумме выходит, что самая длинная запись будет составлять 5+2048+8+16=2077 байт.
Calculations
Database
Дано:
- отношение чтений к записям 200 к 1.
- 100 млн запросов в месяц
- максимальный размер одной записи 2077 байт
Тогда:
- из 100 млн запросов в месяц на чтение было 99,5 млн было на чтение и 0,5 млн на запись
- 200 * (100 млн / (200 + 1))
- 1 * (100 млн / (200 + 1))
- всего за 100 лет будет создано 0,5 млн * 12 месяцев * 100 лет = 600 млн записей
- общий объем данных, который необходимо хранить, равен 600 млн * 2077 байт = 1246200000000 байт / 1024 / 1024 / 1024 = 1160 Гб
Hash
В промежуточных вычислениях выше было выяснено, что всего записей будет 600 млн. Это означает, что сервис должен уметь генерировать такие уникальные короткие ссылки, чтобы вероятность коллизии была равна 0 или приближалась к этому значению.
Скажем, что наш алфавит будет состоять из букв английского языка в нижнем и верхнем регистрах, а также из цифр от 0 до 9. Что составит 62 уникальных символа в алфавите.
Тогда нам необходимо возводить число 62 в степень все выше и выше, пока итоговое число не превысит 600 млн.
Возьмем 62^5 и получим 916 132 832 уникальных комбинации. Этого вполне достаточно для нашей задачи.
Cache
- в кэше должно храниться 20% данных за сутки
- 100 млн / 30 дней / 24 часа / 60 минут / 60 секунд = 38 запросов в секунду
- 200 * (38 / (200 + 1)) = 37 запросов в секунду на чтение
- 1 * (38 / (200 + 1)) = 0,19 запросов в секунду на запись
- 37 чтений в секунду * 60 секунд * 60 минут * 24 часа = 3,2 млн чтений в день
- 3,2 млн чтений в день * 0,2 (20%) = 640к записей * 2077 байт = 1329280000 байт / 1024 / 1024 / 1024 = 1,23 Гб в кэше
API
Create
- для создания сокращенного URL’а потребуется знать оригинальный URL и user_id
- POST /api/v1/create с телом запроса состоящим из одного поля url: string в формате json
- user_id получим из заголовка запроса
- в теле ответа сервер должен вернуть сокращенный URL: поля url: string в формате json
Redirect
- для перенаправления пользователя с сокращенного URL’а на оригинальный сервер должен вернуть ответ с 304 HTTP кодом и указать оригинальный адрес
- GET /[short_url]
Database
Для хранения 1160 Гб данных подойдет любая современная база данных.
Возьмем PostgreSQL.
Для ускорения запросов на поиск сделаем индекс по колонке short_url.
Для обеспечения отказоустойчивости добавим две асинхронные реплики.
Удаления старых данных
Для этого реализуем планировщик задач, который будет раз в сутки удалять все записи из базы данных, у которых значение current_time - created_at ≥ 100 лет.
Cache
Для кэширования 1,23 Гб можем взять практически любой кэш. В данном случае возьмем Redis.
В качестве стратегии записи в кэш выберем Read-Through для кэширования только тех записей, которые запрашиваются.
В качестве алгоритма вытеснения записепй из кэша возьмем Least Frequently Used (LFU) для удаления наименее часто используемых записей.
Load balancer
Типы балансировщиков, которые возьмем:
- client → servers
- возьмем популярный и эффективный балансировщик HTTP запросов - nginx
- servers → databases
- при работе с PostgreSQL хорошим выбором будет pgpool
- servers → caches
- при работе с Redis подойдет любой TCP балансировщик, возьмем haproxy
Стратегии балансировщиков, которые возьмем:
- для нашего количества запросов достаточно будет round-robin
Top-level design